

“Responsible Research and Innovation is a transparent, interactive process by which societal actors and innovators become mutually responsive to each other with a view to the (ethical) acceptability, sustainability and societal desirability of the innovation process and its marketable products( in order to allow a proper embedding of scientific and technological advances in our society)” [1] – Rene von Schomberg
Responsible innovation is defined as a process which aims to increase creativity and opportunities for science and innovation, while at the same time making innovation socially desirable, and taking the public interest into consideration. Responsible innovation accepts that questions and dilemmas can arise from innovation. Purposes and motivations of innovations is often ambiguous, and the impacts of them, beneficial or otherwise, are often unpredictable. Therefore, responsible innovation process explores these aspects of innovation in a thorough manner. The realization of this process requires the collective responsibility of funders, researchers, stakeholders, and the public. They all have key roles to play, which include, but is not limited to, the considerations of risks and regulations.
Responsible data science can be centered around fairness, accuracy, confidentiality and transparency.
Fairness
Training big data and maximizing the objective is the main function of the data science. But it does not guarantee that the outcome is fair because training data might be biased or individually discriminated. Members of some certain groups might be classified, stigmatized and rejected afterwards. Therefore, data science studies must ensure fairness.[2]
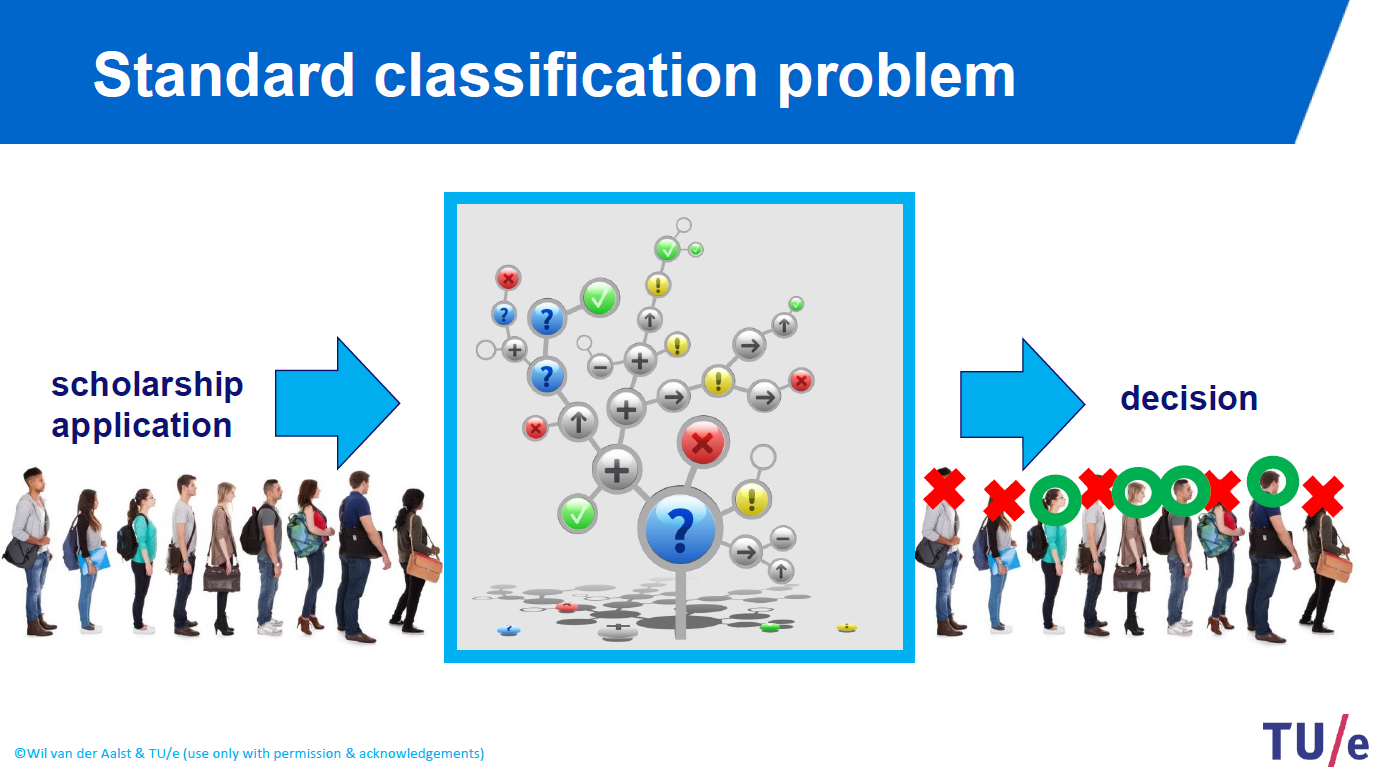
Suppose you are offering a scholorship for a program and you received thousands of applications and you want to choose the best applicant who deserves the scholarship most.
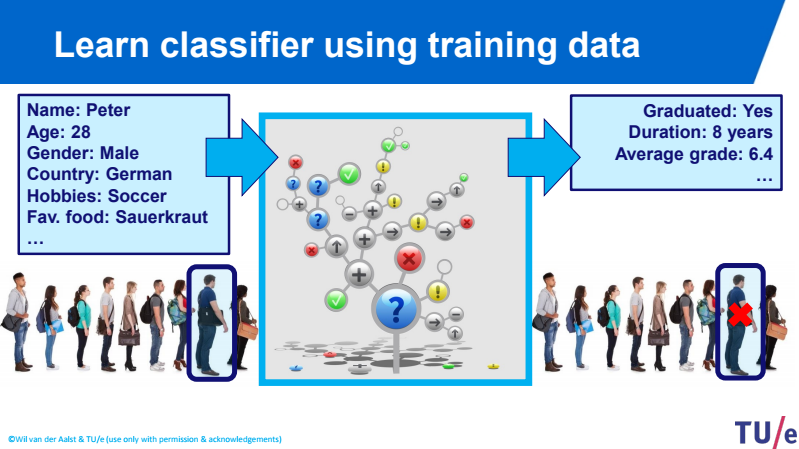
You collect data of each applicant including their: name, age, gender, country, hobbies, favourite food etc. and your criteria to give scholarship are: the applicant should be graduated at least 6.4 grade on average and at least 8 years of work experience.
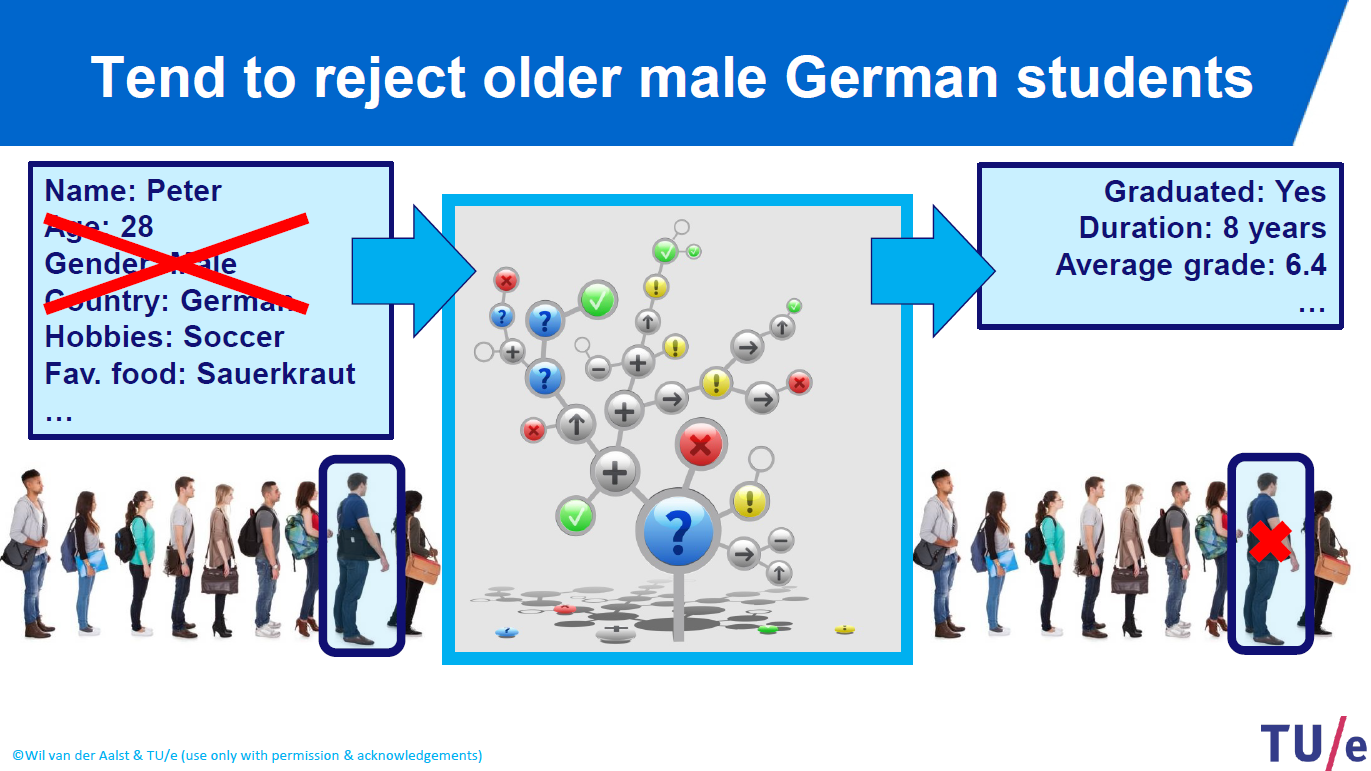
Then you apply some data science techniques by using machine learning algorithms such as linear regression, ridge regression, lasso regression, neural networks, support vector machines algorithm, classification methods etc. If your algorithm is eliminating some applicants just because of their gender it would not be fair!
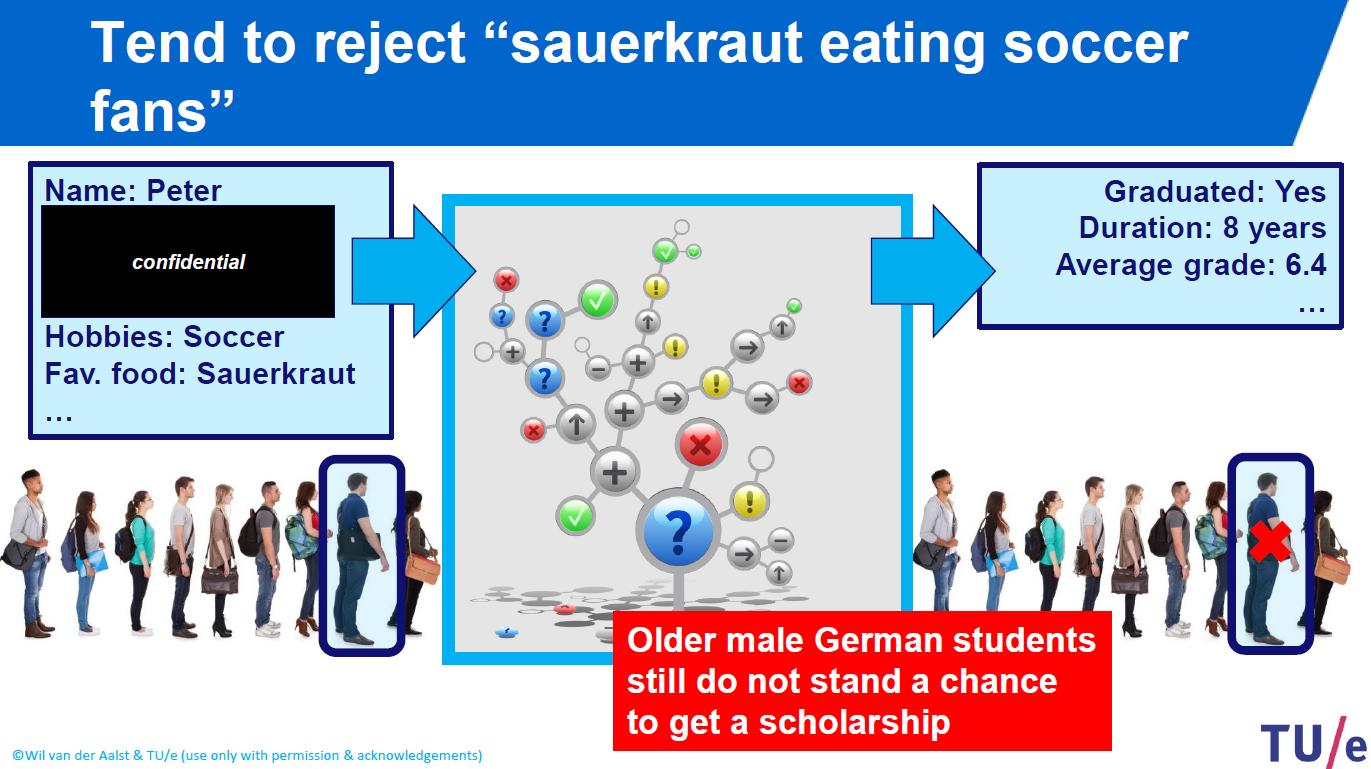
Similarly, if your algorithm is eliminating some applicants just because of their favourite soccer club or food, it would not be fair as well!
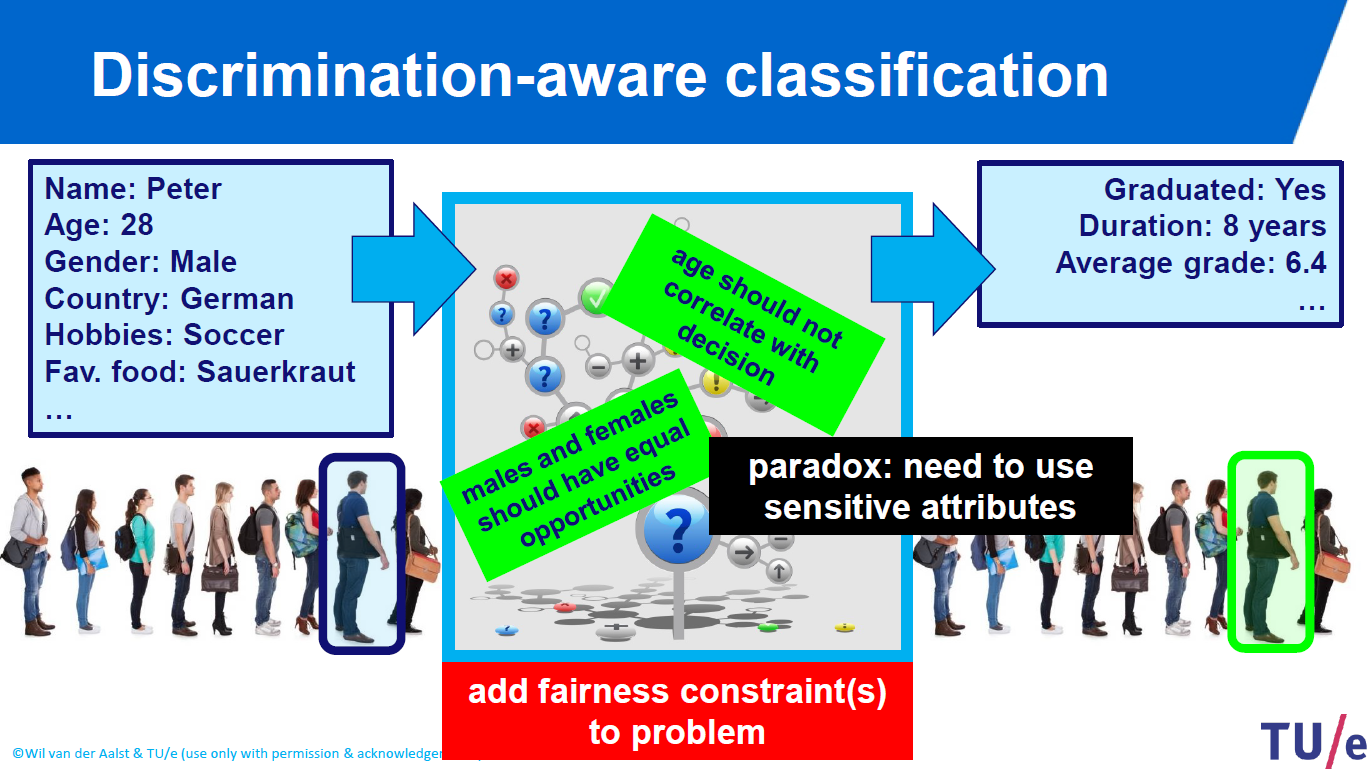
Thus, if you are using data science techniques, you are responsible to add fairness constraints to your problem and consider ethical values.
[3]
Accuracy
Analysis of large or small data sets might produce inaccurate results as well. Variables are used to predict an output. In order to predict an output, there should be either positive or negative correlation between variables and output to get better accuracy.
For example, if you want to predict the “Will someone conduct a terrorist attack?”, and if you select variables for this case as “eye color”, “high school math grade”, “first car brand” then it would be a coincidence or an accident to get an accurate prediction. Therefore, data science studies should not just only present results or make predictions, but also provide accuracy of the output. [2]



 [3]
[3]
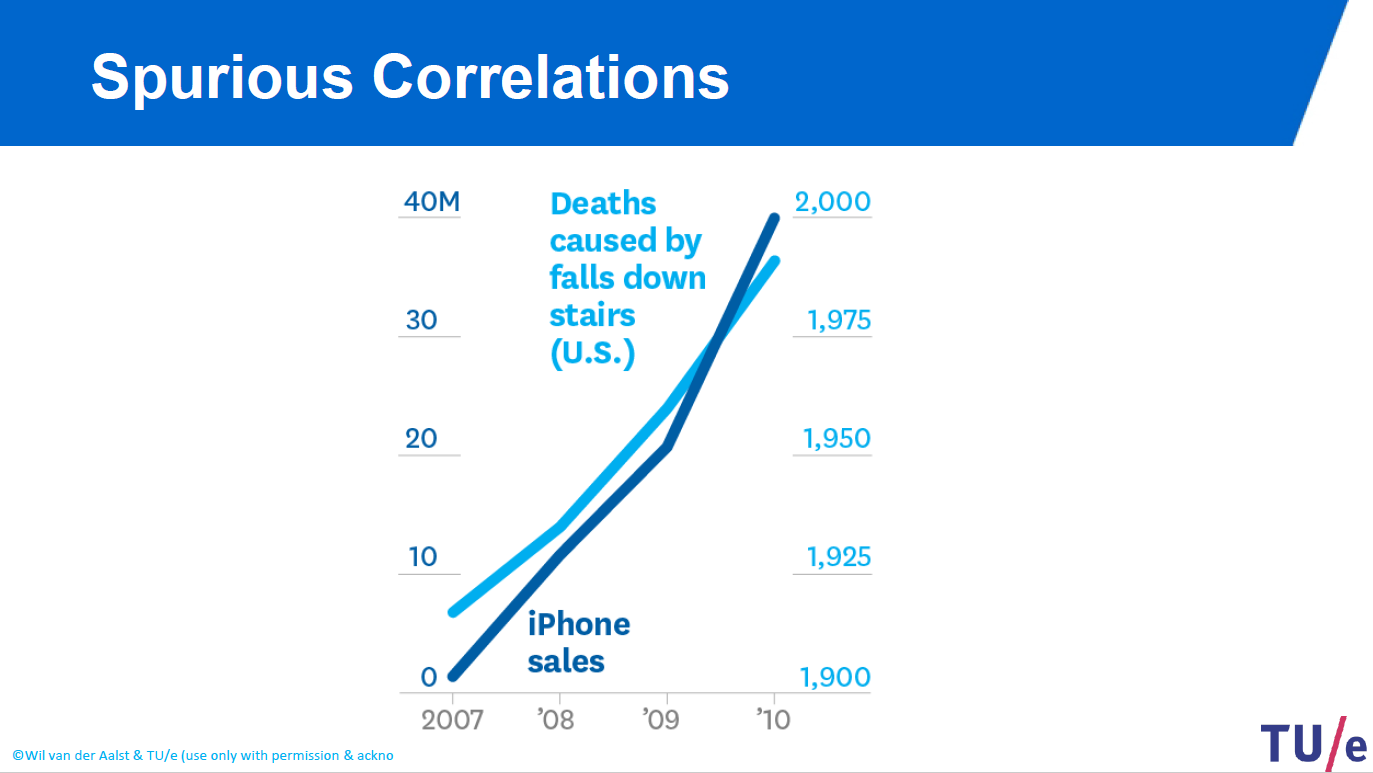
- Similarly, even if it looks like there is a positive correlation between iPhone sales and death caused by falls down stairs in US, they are totaly unrelated events and the correlation is a coincedence. Thus, if you consider these data in the same manner and try to make a prediction, your prediction might not be accurate.
Confidentially
Data science heavily relies on the sharing of data [4]. If people do not trust the data study or worry about its confidentiality, they would not share their data. So that, one of the main objective of data science studies should be exploiting data in a safe and controlled manner. Confidentiality questions need to be addressed from security, legal and ethical perspectives[2]. For example, polymorphic encryption can be used for security perspective which is a code that mutate data while keeping the original algorithm intact. In other words, 1+3 and 6-2 gives exactly same results by using different values and operations [5]. Therefore, another focus of data science should be privacy and the data collected from people should be protected by using technological techniques
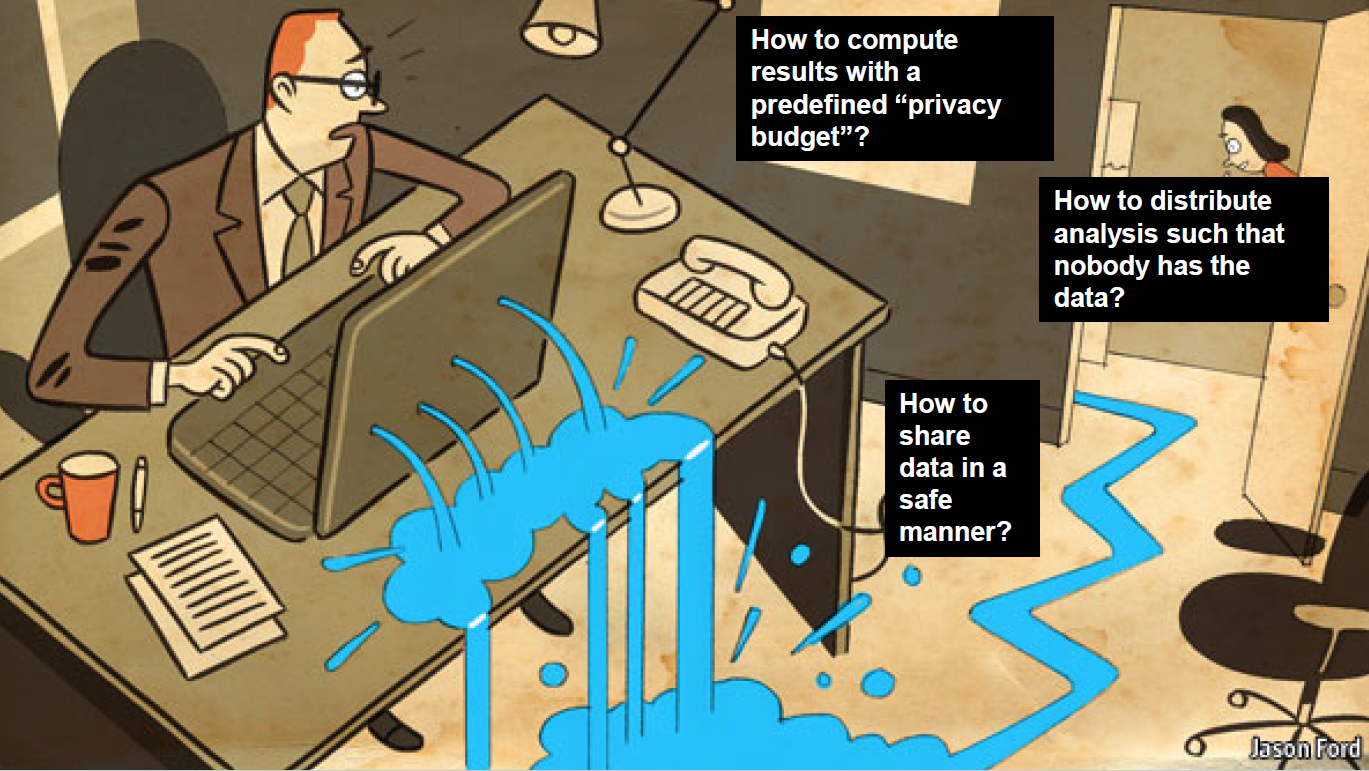 [3]
[3]
Transparency
Data science can be effective if people understand the results and interpret the outcomes easily. Data science should not be like a black box that gets data in and somehow gives an output. There are many steps and actors on the route starting from raw data to the output at the end. For example, neural networks is one of the most popular techniques that is used in data science that gives accurate results. Since it has really complicated algorithm and structure, it is hard to understand for humans. In other words, it serves as a black box that magically makes good decisions, but cannot rationalize them. In some domains, this is unacceptable. Therefore, transparency is another responsibility of data science studies that considers how to present results such that people can easily understand.[2]

[3]
References
[1] Von Schomberg,Rene (2011) ‘Prospects for Technology Assessment in a framework of responsible research and innovation’ in: Technikfolgen abschätzen lehren: Bildungspotenziale transdisziplinärer Methode, P.39-61, Wiesbaden: Springer VS [2 ] van der Aalst, W. M. P., Bichler, M. & Heinzl, A. (2017). Responsible Data Science.. Business & Information Systems Engineering, 59, 311-313. [3] Aalst, W. (n.d.). Responsible Data Science Ensuring Fairness, Accuracy, Confidentiality, and Transparency (FACT). [4] Dwork, C. (2011). A firm foundation for private data analysis. Commun. ACM, 54, 86-95. doi: 10.1145/1866739.1866758 [5] Hildebrandt, M., Jacobs, B., Meijer, C., Ruiter, J.D., & Verheul, E.R. (2016). Polymorphic Encryption and Pseudonymisation for Personalised Healthcare. IACR Cryptology ePrint Archive, 2016, 411.